对常见文件文件头和隐写术做个归纳总结。
一、文件头文件尾 1、图片
文件头:FF D8 FF
未压缩的前4字节 00 00 02 00
RLE压缩的前5字节 00 00 10 00 00
文件头:89 50 4E 47 0D 0A 1A 0A
文件头:47 49 46 38 39(37) 61
文件头:42 4D
文件头标识(2 bytes) 42(B) 4D(M)
文件头:49 49 2A 00
文件头:00 00 01 00
文件头:38 42 50 53
2、office文件
MS Word/Excel (xls.or.doc)
文件头:D0 CF 11 E0
文件头:50 4B 03 04
文件头:53 74 61 6E 64 61 72 64 20 4A
文件头:FF 57 50 43
文件头:25 50 44 46 2D 31 2E
application/vnd.visio(vsd)
文件头:D0 CF 11 E0 A1 B1 1A E1
Email [thorough only] (eml)
文件头:44 65 6C 69 76 65 72 79 2D 64 61 74 65 3A
文件头:CF AD 12 FE C5 FD 74 6F
文件头:21 42 44 4E
文件头:7B 5C 72 74 66
文件头:Unicode:FE FF
Unicode big endian:FF FE
UTF-8:EF BB BF
ANSI编码是没有文件头的
3、压缩包文件
文件头:50 4B 03 04
文件尾:50 4B
文件头:52 61 72 21 1A 07 00
文件尾:C4 3D 7B 00 40 07 00
文件头:4C 5A 49 50
4、音频文件
文件头:57 41 56 45
52 49 46 46 xx xx xx xx 57 41 56 45 66 6D 74 20
文件头: 4D 54 68 64
文件头:FF F1(9)
文件头:4D 41 43 20
5、视频文件
文件头:41 56 49 20
文件头:2E 72 61 FD
文件头:2E 52 4D 46
文件头:00 00 01 BA(3)
文件头:6D 6F 6F 76
文件头:30 26 B2 75 8E 66 CF 11
文件头:4D 54 68 64
6、代码文件
文件头:3C 3F 78 6D 6C
文件头:68 74 6D 6C 3E
文件头:AC 9E BD 8F
文件头:E3 82 85 96
7、其他类型
文件头:30 82 03 C9
文件头:41 43 31 30
文件头:4C 00 00 00
文件头:52 45 47 45 44 49 54 34
文件头:CA FE BA BE
文件头:0A 0D 0D 0A
二、图片隐写 1、附加式的图片隐写 操作系统识别,从文件头标志,到文件的结束标志位
(1)附加字符串 最简单的是附加字符串
附加方法
识别方法
winhex直接看
notepad也可以看
linux的strings指令
liunx的exiftool(查看隐藏信息)
应用
(2)隐藏压缩文件 可以把压缩文件藏在图片文件尾后
附加方法
识别方法
有些直接改扩展名就可以用
linux的binwalk指令参数-e
stegsolve分离
winhex复制压缩文件内容重新保存
liunx的foremost指令
liunx的outguess指令(outguess -k ‘密码’ -r 图片 保存的位置 )
liunx的steghide指令(steghide extract -sf 图片名称 -p 密码)
2、基于文件结构的图片隐写 主要是针对PNG图片
标准的PNG文件结构应包括:
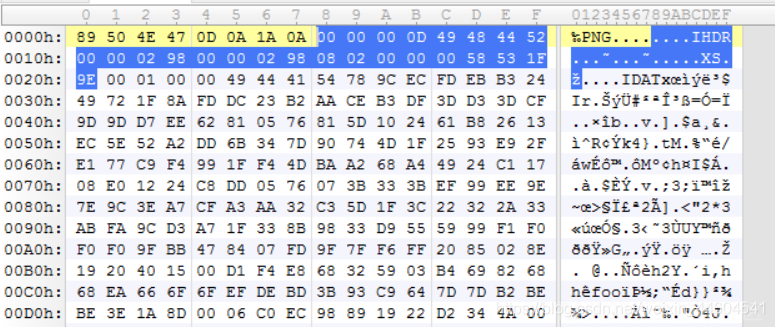
(1)png图片文件头数据块(IHDR) PNG图片的第一个数据块
一张PNG图片仅有一个IHDR数据块
包括了图片的宽,高,图像深度,颜色类型,压缩方法等信息
蓝色部分就是IHDR
可以修改高度值或宽度值对部分信息进行隐藏
如果图片原本是800(宽)*600(高),然后图片的高度从600变成500
这样下面800×100区域的信息就无法从图片中显示出来,我们可见的只有上方800*500的区域,这样就达成了图片隐写的目的
同理可知图片的宽度也可以进行类似的修改以达到隐藏信息的目的
识别方法
(2)IDAT 数据块
存储实际的数据
在数据流中可包含多个连续顺序的图像数据块
写入一个多余的IDAT也不会多大影响肉眼对图片的观察
识别方法
用pngcheck对图片进行检测pngcheck -v hidden.png
可能会出现一个size为0的异常块
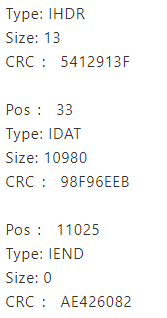
提取内容的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #!/usr/bin/python2 from struct import unpack from binascii import hexlify, unhexlify import sys, zlib # Returns [Position, Chunk Size, Chunk Type, Chunk Data, Chunk CRC] def getChunk(buf, pos): a = [] a.append(pos) size = unpack('!I', buf[pos:pos+4])[0] # Chunk Size a.append(buf[pos:pos+4]) # Chunk Type a.append(buf[pos+4:pos+8]) # Chunk Data a.append(buf[pos+8:pos+8+size]) # Chunk CRC a.append(buf[pos+8+size:pos+12+size]) return a def printChunk(buf, pos): print 'Pos : '+str(pos)+'' print 'Type: ' + str(buf[pos+4:pos+8]) size = unpack('!I', buf[pos:pos+4])[0] print 'Size: ' + str(size) #print 'Cont: ' + str(hexlify(buf[pos+8:pos+8+size])) print 'CRC : ' + str(hexlify(buf[pos+size+8:pos+size+12]).upper()) print if len(sys.argv)!=2: print 'Usage: ./this Stegano_PNG' sys.exit(2) buf = open(sys.argv[1]).read() pos=0 print "PNG Signature: " + str(unpack('cccccccc', buf[pos:pos+8])) pos+=8 chunks = [] for i in range(3): chunks.append(getChunk(buf, pos)) printChunk(buf, pos) pos+=unpack('!I',chunks[i][1])[0]+12 decompressed = zlib.decompress(chunks[1][3]) # Decompressed data length = height x (width * 3 + 1) print "Data length in PNG file : ", len(chunks[1][3]) print "Decompressed data length: ", len(decompressed) height = unpack('!I',(chunks[0][3][4:8]))[0] width = unpack('!I',(chunks[0][3][:4]))[0] blocksize = width * 3 + 1 filterbits = '' for i in range(0,len(decompressed),blocksize): bit = unpack('2401c', decompressed[i:i+blocksize])[0] if bit == '\x00': filterbits+='0' elif bit == '\x01': filterbits+='1' else: print 'Bit is not 0 or 1... Default is 0 - MAGIC!' sys.exit(3) s = filterbits endianess_filterbits = [filterbits[i:i+8][::-1] for i in xrange(0, len(filterbits), 8)] flag = '' for x in endianess_filterbits: if x=='00000000': break flag += unhexlify('%x' % int('0b'+str(x), 2)) print 'Flag: ' + flag
3、LSB隐写 LSB,最低有效位,英文是Least Significant Bit
容量大、嵌入速度快、对载体图像质量影响小
在PNG和BMP上可以实现
原理
图片中的像素一般是由三种颜色组成,即三原色(红绿蓝),由这三种原色可以组成其他各种颜色
在png图片的存储中,每个颜色占有8bit,即有256种颜色,一共包含256的三次方颜色,即16777216种颜色
人类的眼睛可以区分约1,000万种不同的颜色,剩下无法区分的颜色就有6777216
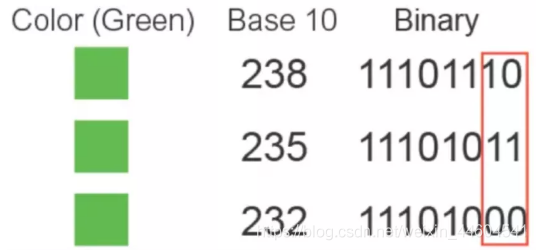
LSB隐写就是修改了像素中的最低位,把一些信息隐藏起来
给个直观例子
这人眼看不出颜色区别,但最低位不一样
嵌入脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 from PIL import Image import math class LSB: def __init__(self): self.im=None def load_bmp(self,bmp_file): self.im=Image.open(bmp_file) self.w,self.h=self.im.size self.available_info_len=self.w*self.h # 不是绝对可靠的 print ("Load>> 可嵌入",self.available_info_len,"bits的信息") def write(self,info): """先嵌入信息的长度,然后嵌入信息""" info=self._set_info_len(info) info_len=len(info) info_index=0 im_index=0 while True: if info_index>=info_len: break data=info[info_index] x,y=self._get_xy(im_index) self._write(x,y,data) info_index+=1 im_index+=1 def save(self,filename): self.im.save(filename) def read(self): """先读出信息的长度,然后读出信息""" _len,im_index=self._get_info_len() info=[] for i in range(im_index,im_index+_len): x,y=self._get_xy(i) data=self._read(x,y) info.append(data) return info #===============================================================# def _get_xy(self,l): return l%self.w,int(l/self.w) def _set_info_len(self,info): l=int(math.log(self.available_info_len,2))+1 info_len=[0]*l _len=len(info) info_len[-len(bin(_len))+2:]=[int(i) for i in bin(_len)[2:]] return info_len+info def _get_info_len(self): l=int(math.log(self.w*self.h,2))+1 len_list=[] for i in range(l): x,y=self._get_xy(i) _d=self._read(x,y) len_list.append(str(_d)) _len=''.join(len_list) _len=int(_len,2) return _len,l def _write(self,x,y,data): origin=self.im.getpixel((x,y)) lower_bit=origin%2 if lower_bit==data: pass elif (lower_bit,data) == (0,1): self.im.putpixel((x,y),origin+1) elif (lower_bit,data) == (1,0): self.im.putpixel((x,y),origin-1) def _read(self,x,y): data=self.im.getpixel((x,y)) return data%2 if __name__=="__main__": lsb=LSB() # 写 lsb.load_bmp('test.bmp') info1=[0,1,0,1,1,0,1,0] lsb.write(info1) lsb.save('lsb.bmp') # 读 lsb.load_bmp('lsb.bmp') info2=lsb.read() print (info2)
识别方法
stegsolve,调通道
zsteg,神一样的工具
提取脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from PIL import Image im = Image.open("extracted.bmp") pix = im.load() width, height = im.size extracted_bits = [] for y in range(height): for x in range(width): r, g, b = pix[(x,y)] extracted_bits.append(r & 1) extracted_bits.append(g & 1) extracted_bits.append(b & 1) extracted_byte_bits = [extracted_bits[i:i+8] for i in range(0, len(extracted_bits), 8)] with open("extracted2.bmp", "wb") as out: for byte_bits in extracted_byte_bits: byte_str = ''.join(str(x) for x in byte_bits) byte = chr(int(byte_str, 2)) out.write(byte)
4、基于DCT域的JPG图片隐写 JPEG图像格式使用离散余弦变换(Discrete Cosine Transform,DCT)函数来压缩图像
Jsteg隐写
将秘密信息嵌入在量化后的DCT系数的LSB上
原始值为-1,0,+1的DCT系数除外
量化后的DCT系数中有负数
实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 import math import cv2 import numpy as np def dct(m): m = np.float32(m)/255.0 return cv2.dct(m)*255 class Jsteg: def __init__(self): self.sequence_after_dct=None def set_sequence_after_dct(self,sequence_after_dct): self.sequence_after_dct=sequence_after_dct self.available_info_len=len([i for i in self.sequence_after_dct if i not in (-1,1,0)]) # 不是绝对可靠的 print ("Load>> 可嵌入",self.available_info_len,'bits') def get_sequence_after_dct(self): return self.sequence_after_dct def write(self,info): """先嵌入信息的长度,然后嵌入信息""" info=self._set_info_len(info) info_len=len(info) info_index=0 im_index=0 while True: if info_index>=info_len: break data=info[info_index] if self._write(im_index,data): info_index+=1 im_index+=1 def read(self): """先读出信息的长度,然后读出信息""" _len,sequence_index=self._get_info_len() info=[] info_index=0 while True: if info_index>=_len: break data=self._read(sequence_index) if data!=None: info.append(data) info_index+=1 sequence_index+=1 return info #===============================================================# def _set_info_len(self,info): l=int(math.log(self.available_info_len,2))+1 info_len=[0]*l _len=len(info) info_len[-len(bin(_len))+2:]=[int(i) for i in bin(_len)[2:]] return info_len+info def _get_info_len(self): l=int(math.log(self.available_info_len,2))+1 len_list=[] _l_index=0 _seq_index=0 while True: if _l_index>=l: break _d=self._read(_seq_index) if _d!=None: len_list.append(str(_d)) _l_index+=1 _seq_index+=1 _len=''.join(len_list) _len=int(_len,2) return _len,_seq_index def _write(self,index,data): origin=self.sequence_after_dct[index] if origin in (-1,1,0): return False lower_bit=origin%2 if lower_bit==data: pass elif origin>0: if (lower_bit,data) == (0,1): self.sequence_after_dct[index]=origin+1 elif (lower_bit,data) == (1,0): self.sequence_after_dct[index]=origin-1 elif origin<0: if (lower_bit,data) == (0,1): self.sequence_after_dct[index]=origin-1 elif (lower_bit,data) == (1,0): self.sequence_after_dct[index]=origin+1 return True def _read(self,index): if self.sequence_after_dct[index] not in (-1,1,0): return self.sequence_after_dct[index]%2 else: return None if __name__=="__main__": jsteg=Jsteg() # 写 sequence_after_dct=[-1,0,1]*100+[i for i in range(-7,500)] jsteg.set_sequence_after_dct(sequence_after_dct) info1=[0,1,0,1,1,0,1,0] jsteg.write(info1) sequence_after_dct2=jsteg.get_sequence_after_dct() # 读 jsteg.set_sequence_after_dct(sequence_after_dct2) info2=jsteg.read() print (info2)
Outgusee算法
识别方法
5、数字水印隐写 数字水印(digital watermark)
在数字化的数据内容中嵌入不明显的记号
被嵌入的记号通常是不可见或不可察的
可以通过计算操作检测或者提取
盲水印
对图像进行傅里叶变换,起始是一个二维离散傅里叶变换,图像的频率是指图像灰度变换的强烈程度
将二维图像由空间域变为频域后,图像上的每个点的值都变成了复数,也就是所谓的复频域,通过复数的实部和虚部,可以计算出幅值和相位,计算幅值即对复数取模值,将取模值后的矩阵显示出来,即为其频谱图
对模值再取对数,在在0~255的范围内进行归一化,这样才能够准确的反映到图像上,发现数据之间的差别,区分高频和低频分量
识别方法:
6、图片容差隐写 容差
在选取颜色时所设置的选取范围
容差越大,选取的范围也越大
其数值是在0-255之间
容差比较的隐写
若是有两张图片,则对两张图片的每一个像素点进行对比,设置一个容差的阈值α,超出这个阈值的像素点RGB值设置为(255,255,255),若是没超过阈值,则设置该像素点的RGB值为(0,0,0)。因此,通过调整不同的α值,可以使对比生成的图片呈现不同的画面。比如两张图完全一样,设置阈值α为任何值,最后得到的对比图都只会是全黑。若两张图每一个像素点都不同,阈值α设置为1,则对比图将是全白。如果将隐藏信息附加到某些像素点上,这时调整阈值α即可看到隐藏信息。
如果是一张图片,则根据每一像素点周围像素的值进行判断,同样设置一个阈值,若当前像素点超过周围像素点的均值,或者其它的某种规则,则将该像素点RGB值置为(255,255,255),反之则不进行处理,或者设置为全0.这样也可以获得隐藏的信息。
识别方法
7、打乱进制 比如把整个二进制都逆序
识别方法
反序脚本
1 2 3 4 5 6 7 8 9 import os f = open('1',"rb")#二进制形式打开 f = f.read()[::-1] for i in f: ans = str(hex(i))[2:][::-1] if len(ans) == 1: ans = ans + '0' print(ans,end='') #实现反序输出一个文件
翻转脚本
1 2 3 4 5 6 7 8 9 f1=open('task_flag.jpg','rb').read() f1_len=len(f1) f2=open('tt.jpg', 'ab') i=0 while i<f1_len: f2.write(f1[i:i+4][::-1]) i=i+4 f2.close() #实现镜像翻转图片
8、GIF的组合 gif每帧是某个图的一部分
工具
9、YCrCb隐写 gif每帧是某个图的一部分
工具
颜色翻转代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from cv2 import cv2 as cv #需要打开图片的路径,可以是绝对路径或者相对路径,路径中不能出现中文 #读取的彩色图片,是按照 GBR 的形式,数据格式在 0~255 #根据提示不止RGB,opencv中有多种色彩空间,包括 RGB、HSI、HSL、HSV、HSB、YCrCb、CIE XYZ、CIE Lab8种 ''' 使用函数cv2.imread(filepath,flags)读入一副图片 filepath:要读入图片的完整路径 flags:读入图片的标志 cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道 cv2.IMREAD_GRAYSCALE:读入灰度图片 cv2.IMREAD_UNCHANGED:顾名思义,读入完整图片,包括alpha通道 ''' imag=cv.imread('G:/Desktop/211119619784cbdb9fb.png') ''' 用法: cv2.cvtColor(src, code[, dst[, dstCn]]) 参数: src:它是要更改其色彩空间的图像。 code:它是色彩空间转换代码。 dst:它是与src图像大小和深度相同的输出图像。它是一个可选参数。 dstCn:它是目标图像中的频道数。如果参数为0,则通道数自动从src和代码得出。它是一个可选参数。 ''' src=cv.cvtColor(imag,cv.COLOR_BGR2YCrCb) Y,Cr,Cb=cv.split(src) ''' 使用函数cv2.imwrite(file,img,num)保存一个图像。 第一个参数是要保存的文件名,第二个参数是要保存的图像。 可选的第三个参数,它针对特定的格式:对于JPEG,其表示的是图像的质量, 用0 - 100的整数表示,默认95;对于png ,第三个参数表示的是压缩级别,默认为3 ''' cv.imwrite('G:/Desktop/Y.png',(Y%2)*255) cv.imwrite('G:/Desktop/Cr.png',(Cr%2)*255) cv.imwrite('G:/Desktop/Cb.png',(Cb%2)*255)
三、音频隐写 简单提一下
频谱图藏信息
高低位二进制
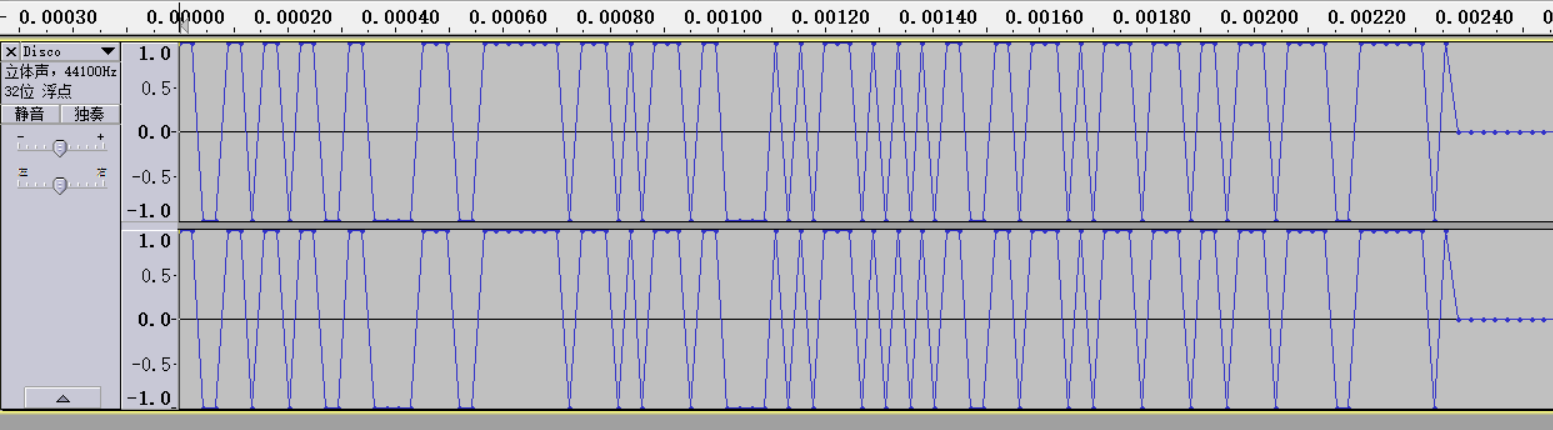
波形藏摩斯密码
MP3Stego
音频中也有LSB
1、摩斯电码 考察点
工具
莫斯电码解密:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 # -*- coding:utf-8 -*- s = input("input the cipher_text Enclose with quotes:") codebook = { 'A':".-", 'B':"-...", 'C':"-.-.", 'D':"-..", 'E':".", 'F':"..-.", 'G':"--.", 'H':"....", 'I':"..", 'J':".---", 'K':"-.-", 'L':".-..", 'M':"--", 'N':"-.", 'O':"---", 'P':".--.", 'Q':"--.-", 'R':".-.", 'S':"...", 'T':"-", 'U':"..-", 'V':".--", 'W':".--", 'X':"-..-", 'Y':"-.--", 'Z':"--..", '1':".----", '2':"..---", '3':"...---", '4':"....-", '5':".....", '6':"-....", '7':"--...", '8':"---..", '9':"----.", '0':"-----", '.':".━.━.━", '?':"..--..", '!':"-.-.--", '(':"-.--.", '@':".--.-.", ':':"---...", '=':"-...-", '-':"-....-", ')':"-.--.-", '+':".-.-.", ',':"--..--", '\'':".----.", '_':"..--.-", '$':"...-..-", ';':"-.-.-.", '/':"-..-.", '\"':".-..-.", } clear = "" cipher = "" while 1: ss = s.split(" "); for c in ss: for k in codebook.keys(): if codebook[k] == c: cipher+=k print(cipher) break;
除了使用本地脚本,还有很多在线网站可以解密
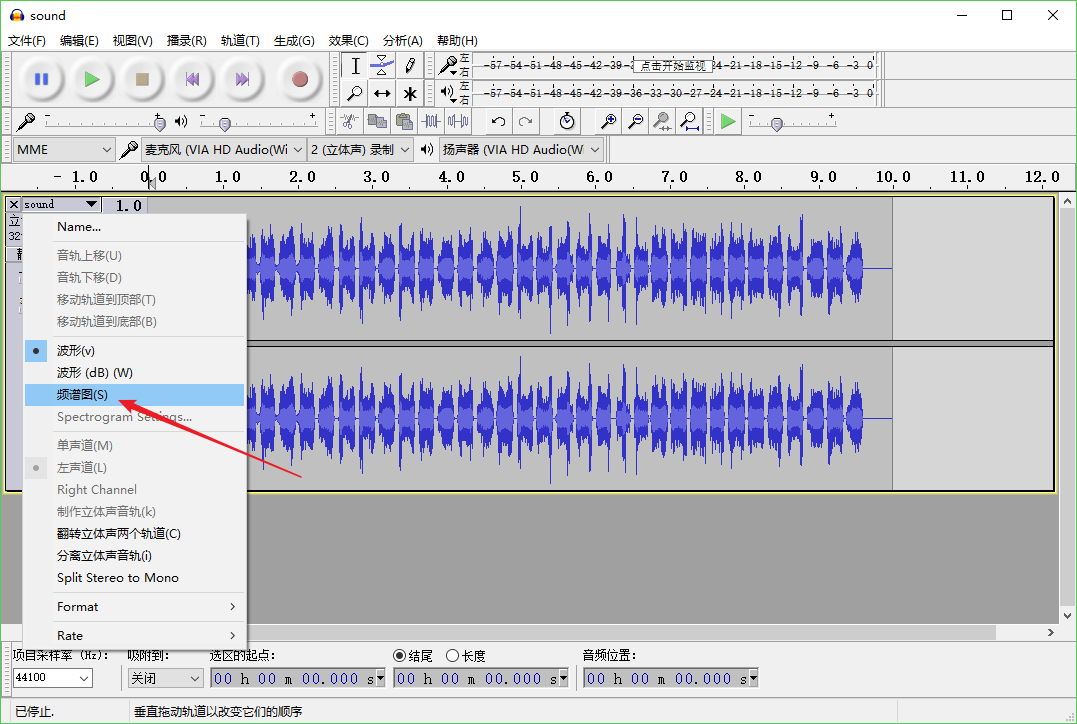
2、频谱图 考察点
工具
识别方法
这里使用工具 Audacity 去打开 wav文件。切换到频谱图去观察:
3、波形图 考察点
工具
识别方法
以高为 1 低为 0,转换得到 01 字符串:
1 110011011011001100001110011111110111010111011000010101110101010110011011101011101110110111011110011111101
一共105位,额,不符合8位一个字符,符合7位,于是在每个7位之前加个0,得到:
1 2 3 01100110,01101100,01100001,01100111,01111011,01010111,00110000 01010111,00101010,01100110,01110101,01101110,01101110,01111001, 01111101
然后二进制转十进制,然后再转为 ASCII,得到 flag。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1100110 102 1101100 108 1100001 97 1100111 103 1111011 123 1010111 87 0110000 48 1010111 87 0101010 42 1100110 102 1110101 117 1101110 110 1101110 110 1111001 121 1111101 125 flag{W0W*funny}
感觉这题的难点不是从频谱中读取二进制数据。
个人觉得从读出的二进制数据想到 8 位一组补上 0 ,这一步还是比较难的,得保持数据的敏感性才可以
4、MP3 隐写 概览
ISCC-2016:Music Never Sleep
考察点
工具
在压缩过程中,MP3Stego 会将信息隐藏在 MP3 文件中。数据首先被压缩、加密,然后隐藏在 MP3 比特流中。
基本介绍和用法如下:
1 2 encode -E hidden_text.txt -P pass svega.wav svega_stego.mp3 decode -X -P pass svega_stego.mp3
听音频无异常猜测使用隐写软件隐藏数据,搜索 mp3 里面的关键字符串:
得到密码后使用 Mp3Stego解密:
1 decode.exe -X ISCC2016.mp3 -P bfsiscc2016
得到文件 iscc2016.mp3.txt,其内容是:
1 Flag is SkYzWEk0M1JOWlNHWTJTRktKUkdJTVpXRzVSV0U2REdHTVpHT1pZPQ== ???
base64 && base32 后得到 flag:
none
1 flag: IwtsqndljERbd367cbxf32gg
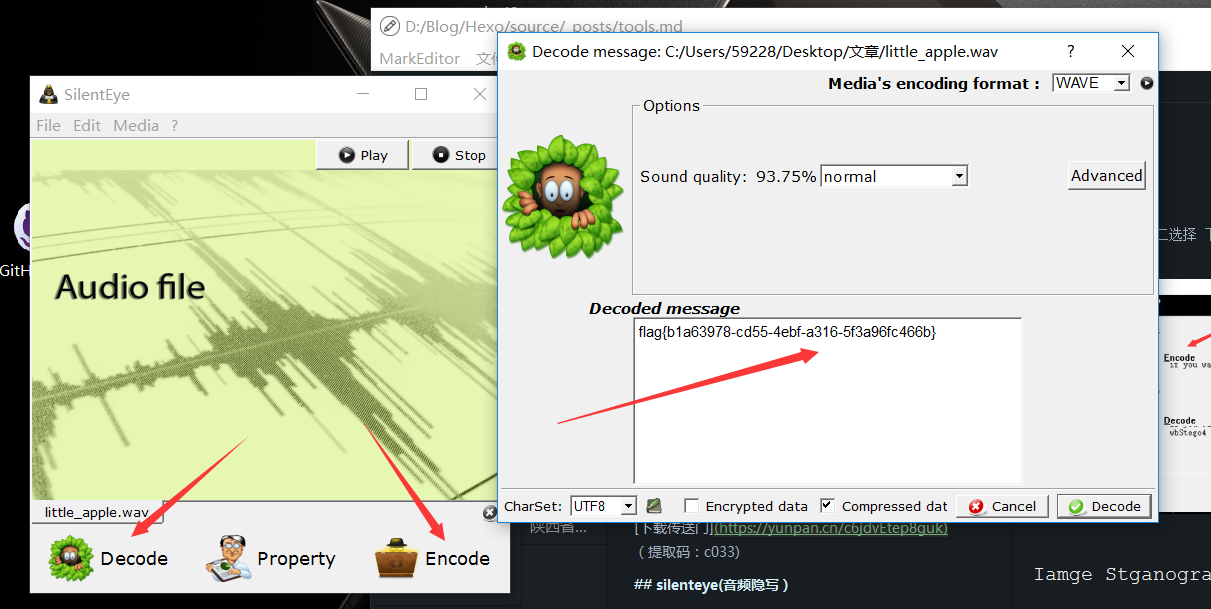
5、SilentEye 考察点
工具
SilentEye 是一个跨平台的应用程序设计,可以轻松地使用隐写术,在这种情况下,可以将消息隐藏到图片或声音中。它提供了一个很好的界面,并通过使用插件系统轻松集成了新的隐写算法和加密过程。
Writeup
直接使用 slienteye 这个工具即可 :
6、综合 工具
Writeup
解压 mp3,首先使用 Mp3Stego解密 mp3 文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 D:\soft\MP3Stego_1_1_18\MP3Stego λ Decode.exe -X C:\Users\CTF\Desktop\CTF\misc\hong_Ksfw02V.mp3 MP3StegoEncoder 1.1.17 See README file for copyright info Input file = 'C:\Users\CTF\Desktop\CTF\misc\hong_Ksfw02V.mp3' output file = 'C:\Users\CTF\Desktop\CTF\misc\hong_Ksfw02V.mp3.pcm' Will attempt to extract hidden information. Output: C:\Users\CTF\Desktop\CTF\misc\hong_Ksfw02V.mp3.txt Enter a passphrase: Confirm your passphrase: the bit stream file C:\Users\CTF\Desktop\CTF\misc\hong_Ksfw02V.mp3 is a BINARY file HDR: s=FFF, id =1, l=3, ep=off, br=9, sf=0, pd=1, pr =0, m=0, js=0, c=0, o=0, e=0 alg.=MPEG-1, layer=III, tot bitrate=128, sfrq=44.1 mode=stereo, sblim=32, jsbd=32, ch=2 [Frame 1265]Avg slots/frame = 417.631; b/smp = 2.90; br = 127.899 kbps Decoding of "C:\Users\CTF\Desktop\CTF\misc\hong_Ksfw02V.mp3" is finished The decoded PCM output file name is "C:\Users\CTF\Desktop\CTF\misc\hong_Ksfw02V.mp3.pcm"
得到一个 txt 文件内容是:
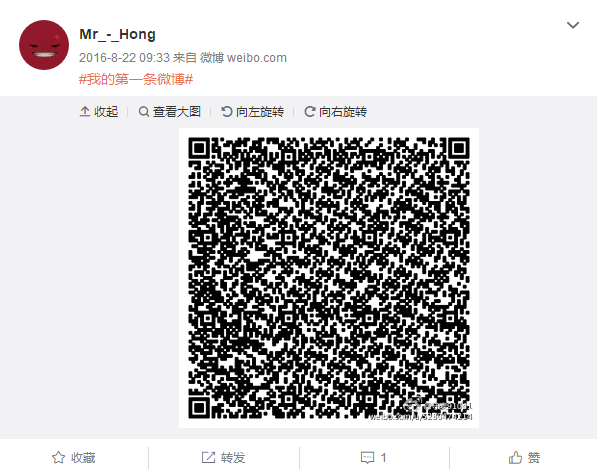
访问得到一张二维码:
读取二维码得到内容为:
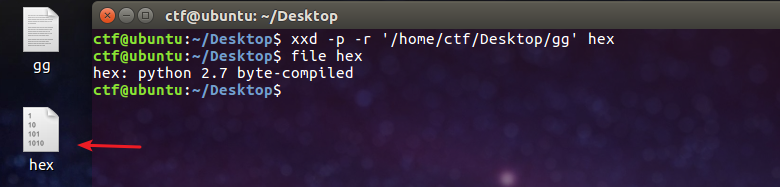
1 03 F30D0AC252BA576300000000000000000100000040000000730D0000006400008400005A00006401005328020000006300000000030000000F000000430000007363000000640100640200640300640400640500640600640400640700640800640300640400640900640300640900640A00670F007D0000640B007D0100781E007C0000445D16007D02007C01007400007C0200830100377D0100714000577C0100474864000053280C0000004E697A00000069680000006969000000695F0000006966000000697500000069730000006961000000696E0000006967000000740000000028010000007403000000636872280300000074030000007374727404000000666C6167740100000069280000000028000000007304000000622E70795203000000010000007326000000000103010301030103010301030103010301030103010301030103010301090106010D0114024E280100000052030000002800000000280000000028000000007304000000622E707974080000003C6D6F64756C653E010000007300000000
将二进制内容保存文件为gg,然后用xxd命令生成一个 hex 文件:
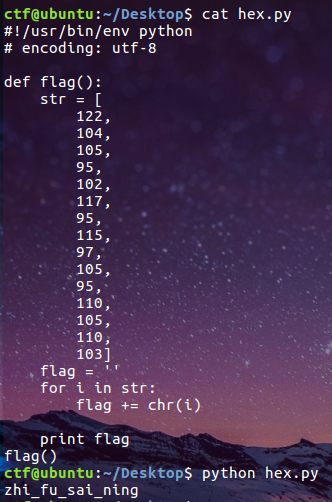
用 file 命令查看下是一个 python 2.7的编译文件,手动改为 hex.pyc然后在线反编译一下文件得到源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def flag (): str = [ 122 , 104 , 105 , 95 , 102 , 117 , 95 , 115 , 97 , 105 , 95 , 110 , 105 , 110 , 103 ] flag = '' for i in str : flag += chr (i) print flag
代码最后加上flag()调用 flag 函数输出 flag:
7、mp3文件private bit隐写 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import re import binascii n = 235986 result = '' fina = '' number = 0 list = [0,1,26,50,75,99,124,148,173,197,222,246,271,295,320,344,369,393,418] file = open('cb1bc8789569146483da7bd65ee4a063.mp3','rb') while n < 1369844 : file.seek(n,0) if number in list: n += 417 else: n += 418 file_read_result = file.read(1) read_content = bin(ord(file_read_result))[-1] result = result + read_content number += 1 #print result fina = '' textArr = re.findall('.{'+str(8)+'}', result) # textArr.append(result[(len(textArr)*8):]) for i in textArr: fina = fina + chr(int(i,2)).strip('\n') print fina
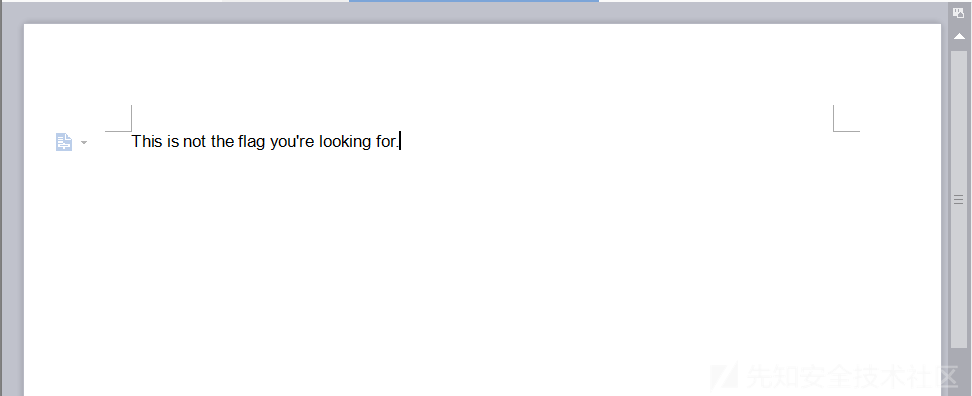
四、电子文档隐写 1、隐藏文字 利用隐藏文本功能进行隐写 首先打开,flag.docFlag in here。,我们就可以猜测,flag是被隐藏起来了
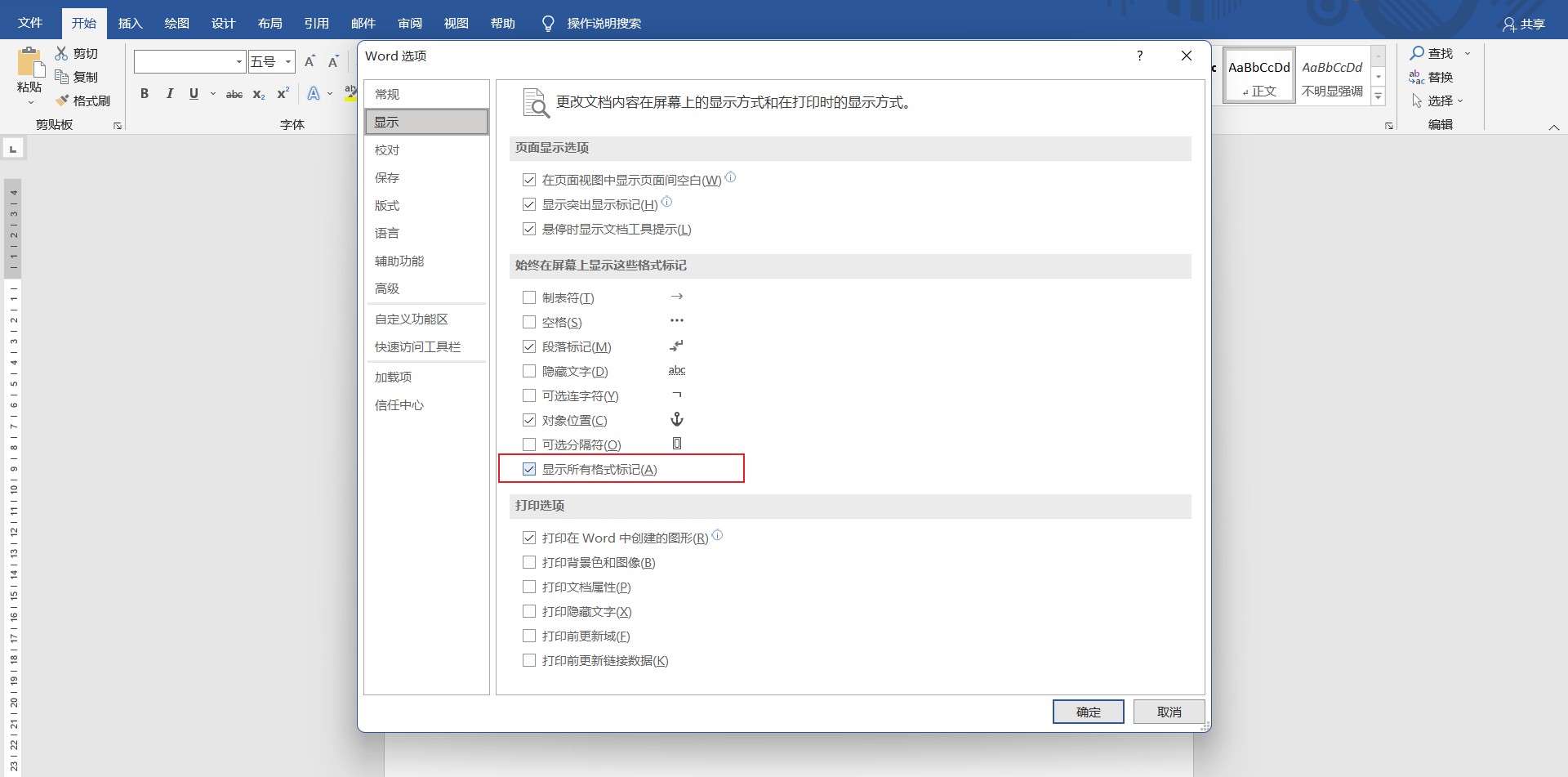
开启隐藏文字显示功能,查看flag是否被隐写
word文档在此处
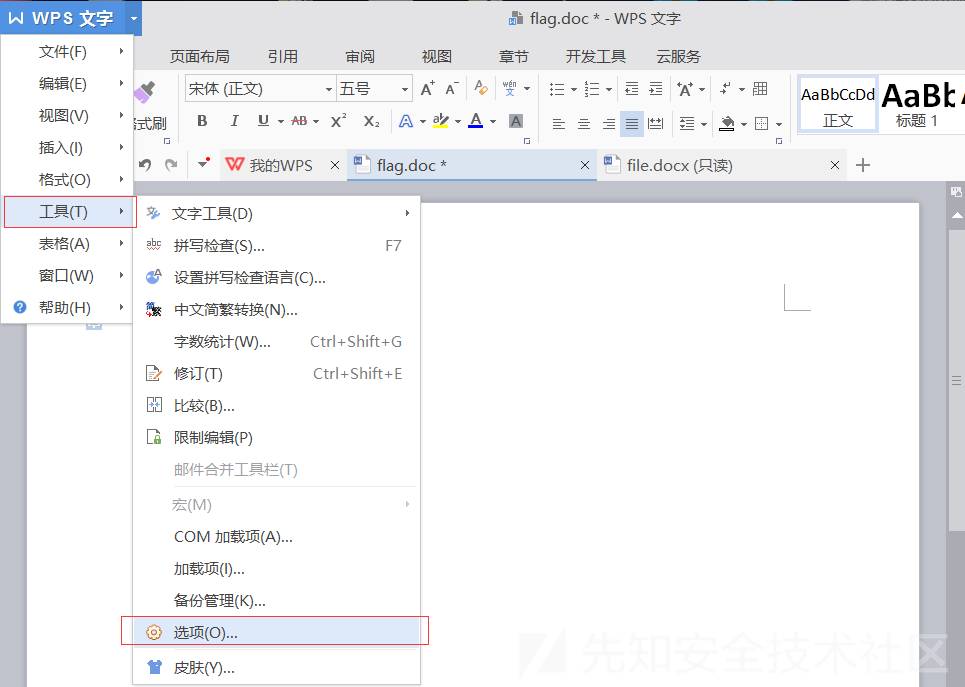
wps在菜单栏中,找到文件,移动鼠标到工具一栏,选择选项功能。
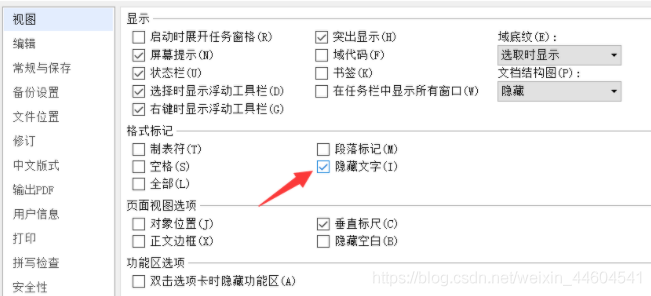
在弹出来的菜单栏中,找到隐藏文字功能,选择使其打上对勾。
点击确定,回到文字编辑界面就能看到flag了。
word文档的xml转换 我们可以将word文档转换成xml格式,当然反过来我们也可以将xml转换成word文档,这导致了我们如果重新打包为word文档的过程中,有可能被隐藏进其他数据。
首先,找到文件并打开文件查看
尝试分离文件内容
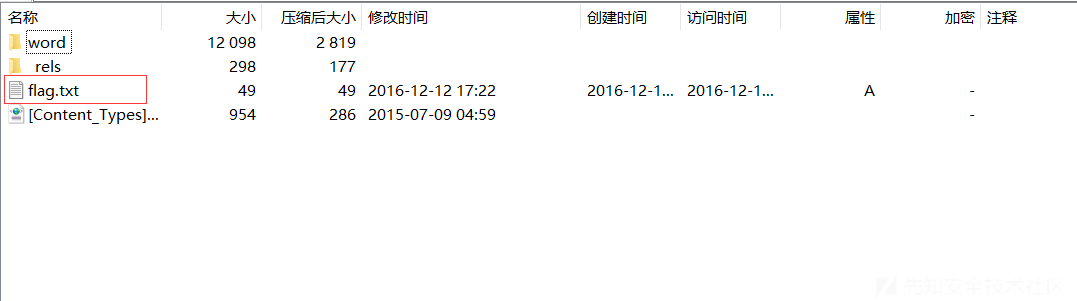
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 +bash-4.3$ file file.docx file.docx: Zip archive data, at least v2.0 to extract +bash-4.3$ 7z x file.docx -oout 7-Zip [64] 9.20 Copyright (c) 1999-2010 Igor Pavlov 2010-11-18 p7zip Version 9.20 (locale=utf8,Utf16=on,HugeFiles=on,8 CPUs) Processing archive: file.docx Extracting word/numbering.xml Extracting word/settings.xml Extracting word/fontTable.xml Extracting word/styles.xml Extracting word/document.xml Extracting word/_rels/document.xml.rels Extracting _rels/.rels Extracting [Content_Types].xml Extracting flag.txt Everything is Ok
我们会发现又flag.txt的文件被打包在file.docx中,直接用7z等压缩包工具打开file.docx
打开,flag.txt文件,就能看到flag了。
2、文件隐藏 PDF隐写中,我们最常用,也是最熟知的工具就是wbStego4open,这是可以把文件隐藏到BMP,TXT,HTM和PDF文件中的工具,当然,这里我们只用他来最为以PDF为载体进行隐写的工具。
在工具目录中找到 wbStego4open,使用工具载入文档,
Step 1 是文件介绍
Step 2 中,我们选择Decode,
Step 3 我们选择目标文件
Step 4 输入加密密码,这里我是空密码,直接跳过
Step 5 为保存文件为 flag.txt
最后打开保存后的文件,flag.txt,就能得到flag了。
总结 CTF MISC 这块还是建议大家靠兴趣去刷题,因为学这玩意出来不一定可以找到工作,如果不是真正喜欢这个,不建议大家去做专职的 MISC 手,CTF 竞赛中二进制是主力,Web 次之。就业方面 Web 就业机会要多于二进制,MISC、密码学这里的方向就业岗位真的不多,所以还是建议 Web 手或者二进制手兼职刷一些 MISC 题目,不要主次颠倒了。



 微信
微信

