本文主要记录base64原理及base64隐写的原理。
base64加密 base64 是一种编码方式, 是一种可逆的编码方式
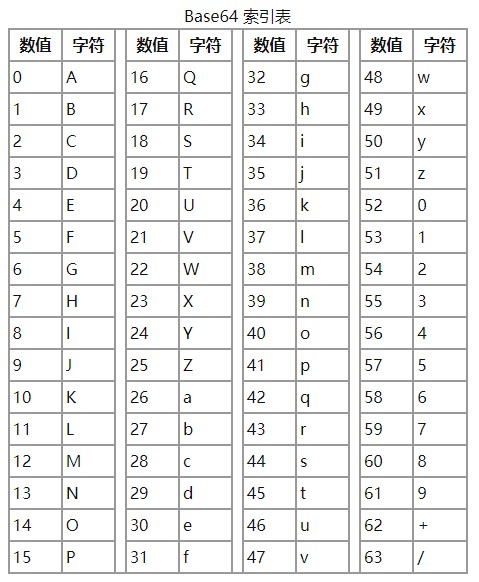
编码后的数据使用64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串
一共64个字符:26+26+10+1+1=64,外加“=”符号用作后缀用途。
因为2的6次方等于64,所以需要6位二进制来表示,表示数值从0到63,对应上表的64个数值。
加密过程 1 2 3 4 5 1.首先将待编码的内容转换成8位二进制,每3个字符为一组 2.如果编码前的长度是3n+1,编码后的内容最后面补上2个 ‘=’,如果编码前的长度是3n+2,编码后的内容最后面补上1个 ‘=’ 3.再将每一组的二进制内容拆分成6位的二进制,不足6位的后面补足0 4.每个6进制的数字前面补足0,保证变成8位二进制 5.将补足后的内容根据base64编码表转换成base64内容输出
首先是将明文字符串转换为二进制的形式,此处建议明文字符串使用ASCII字符,防止后期界面的时候不可打印
在加密过程中有两种情况:
明文字符串长度是三的倍数 用len作为输入的明文
首先需要将len字符串转换为二进制的形式(此处需要在不足8位的前面补充0,以便凑满8个二进制位)
1 2 3 4 ASCII字符 对应的二进制值 l 01101100 e 01100101 n 01101110
将二进制组合成一个字符串:011011000110010101101110,可以看到正好是3*8=24位
然后按照6位一分可以正好分成24/6=4份,所以最后的密文的长度是4
将4个字符整理出对应的10进制,然后根据10进制的值去表格中找对应的字符的值,然后拼接形成密文bGVu
1 2 3 4 5 6 011011+000110+010101+101110 二进制 十进制 base64表中对应的字符 011011 27 b 000110 6 G 010101 21 V 101110 46 u
即len经过base64加密之后的密文是bGVu
根据站长工具验证,上述结论正确
明文不是三的倍数 当明文不是三个倍数时,明文转成二进制会导致后面不能够被6整除有可能,于是需要涉及填充字符
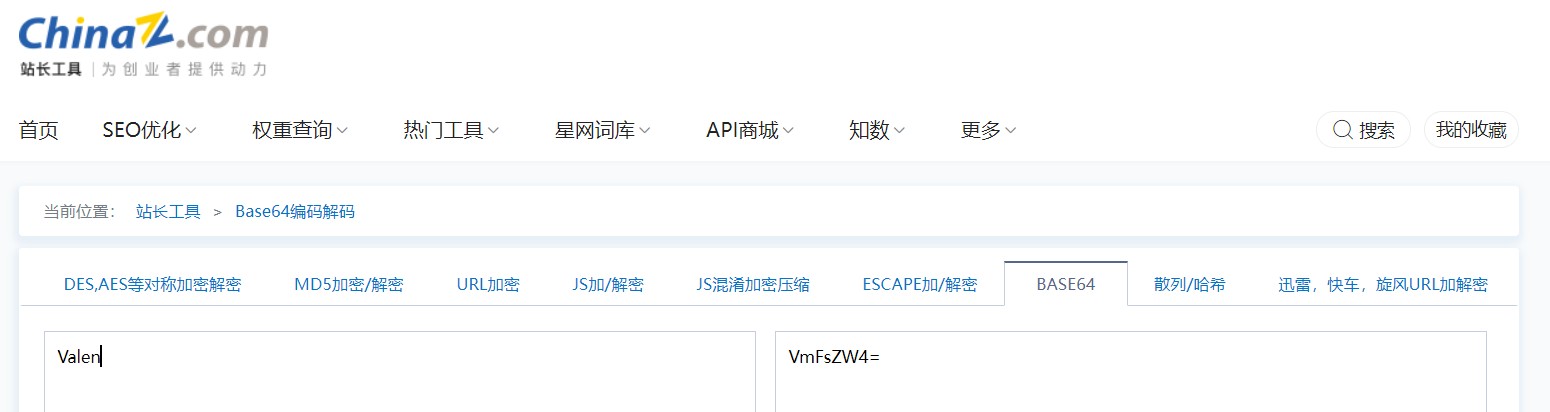
将Valen作为明文,首先将明文转成二进制
1 2 3 4 5 6 ASCII字符 对应的二进制值 V 01010110 a 01100001 l 01101100 e 01100101 n 01101110
将二进制组合成一个字符串:0101011001100001011011000110010101101110,可以看到长度是5*8=24位
按照6位是不能全部分开,可以看到最后一个不足6位,但是有4位,所以我们需要补两个0上去
1 2 3 4 5 6 7 8 9 010101+100110+000101+101100+011001+010110+1110 二进制 十进制 base64表中对应的字符 010101 21 V 100110 38 m 000101 5 F 101100 44 s 011001 25 Z 010110 22 W 111000 56 4
可以看到最后一位在后面填充了两个0,此时的密文信息为:VmFsZW4
因为填充了两个0所以需要补充一个等号在密文后面,要是补充了四个0则需要补充两个等号,所以密文最后最多只有两个等号。
即Valen经过base64加密之后的密文是VmFsZW4=
根据站长工具验证,上述结论正确
结论 1.编码后的数据比原始数据略长,为原来的4/3
2.只含有65种字符,大写的A至Z,小写的a至z,数字0到9,以及3种符号+/ =,=最多两个,且在末尾
代码实现 转换步骤
1 2 3 4 5 6 7 第一步 将待转换的字符串分割成一个个字符 第二步 计算每一个字符对应的ASCII码对应的二进制,若不足8位,在前面添加0进行补全 第三步 将得到的所有字符的二进制值,按照6个6个一组划分,若不能整除6,在最末添加0补足6位 第四步 计算6个划分后的二进制值的十进制值,不足八位补0 第五步 按照base64表,查看对应的字符 第六步 根据补0的个数在后面填充=号,两个0对应一个=,四个0对应两个= 第七步 得到最终结果
下面是base64加密原理的python代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import mathstr_dict = {'0' : 'A' , '1' : 'B' , '2' : 'C' , '3' : 'D' , '4' : 'E' , '5' : 'F' , '6' : 'G' , '7' : 'H' , '8' : 'I' , '9' : 'J' ,'10' : 'K' , '11' : 'L' , '12' : 'M' , '13' : 'N' , '14' : 'O' , '15' : 'P' , '16' : 'Q' , '17' : 'R' , '18' : 'S' ,'19' : 'T' , '20' : 'U' , '21' : 'V' , '22' : 'W' , '23' : 'X' , '24' : 'Y' , '25' : 'Z' , '26' : 'a' , '27' : 'b' ,'28' : 'c' , '29' : 'd' , '30' : 'e' , '31' : 'f' , '32' : 'g' , '33' : 'h' , '34' : 'i' , '35' : 'j' , '36' : 'k' ,'37' : 'l' , '38' : 'm' , '39' : 'n' , '40' : 'o' , '41' : 'p' , '42' : 'q' , '43' : 'r' , '44' : 's' , '45' : 't' ,'46' : 'u' , '47' : 'v' , '48' : 'w' , '49' : 'x' , '50' : 'y' , '51' : 'z' , '52' : '0' , '53' : '1' , '54' : '2' ,'55' : '3' , '56' : '4' , '57' : '5' , '58' : '6' , '59' : '7' , '60' : '8' , '61' : '9' , '62' : '+' , '63' : '/' } mingwen = 'valen' print ('明文:' + mingwen)two = '' for m in mingwen: mingwen_two = bin (ord (m)).replace('0b' , '' ) if len (mingwen_two) < 8 : mingwen_two = '0' * (8 - len (mingwen_two)) + mingwen_two two = two + mingwen_two print (mingwen_two) print (m) print ('明文的二进制形式:' + two) two_len = (len (two) / 6 ) two_len = math.ceil(two_len) print ('向上取整个数:{0}' .format (two_len))miwen = '' add_num = 0 for i in range (two_len): check = two[6 * i:6 + 6 * i] if len (check) < 6 : add_num = 6 - len (check) check = check + (str (0 ) * (6 - len (check))) print (check) print (str_dict['{0}' .format (int (check, 2 ))]) miwen += str_dict['{0}' .format (int (check, 2 ))] if add_num != 0 : miwen += '=' * int (add_num / 2 ) print ('密文' + miwen)
base64解密 解密过程 就是加密过程的逆序
1 2 3 4 5 1.根据密文信息从字典中取出对应的键 2.将字符信息转成二进制形式,需要填满6位,等号因为没有就不会被转成二进制 3.根据等号切割二进制位,将所有的二进制分成8位一份的十进制 4.根据得到的十进制去找对应的ASCII字符 5.拼接ASCII字符完成解密
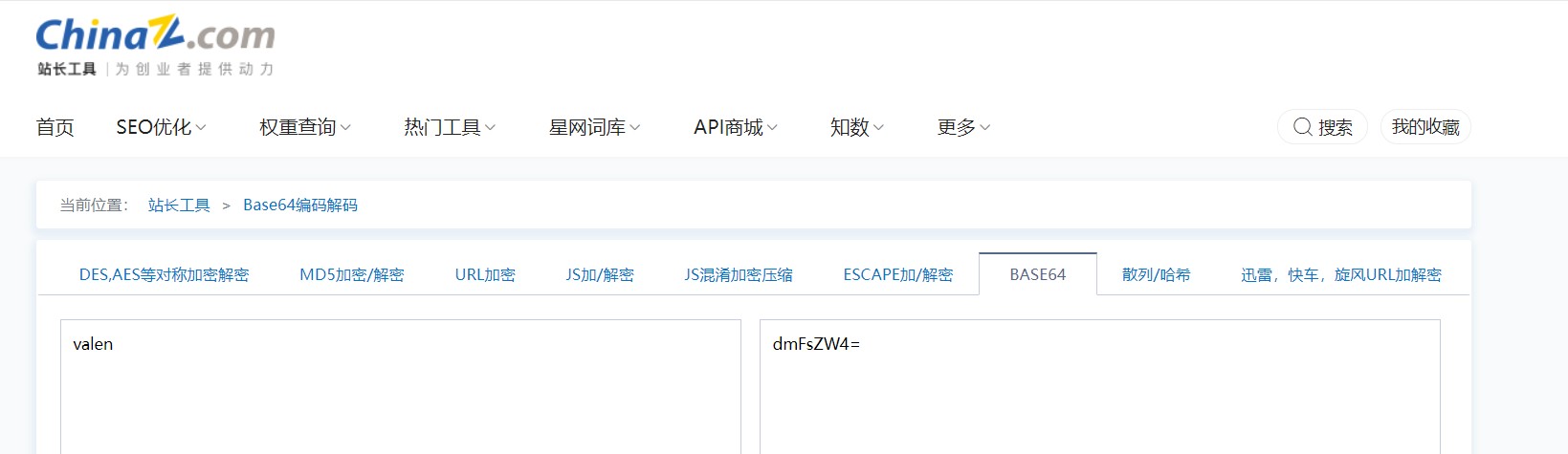
首先密文是dmFsZW4=,切割后得到dmFsZW4,然后得到每个字符在字典中的键,根据键转为二进制
1 2 3 4 5 6 7 8 密文中的字符 字典对应的键值 将键值转成二进制的形式 d 29 011101 m 38 100110 F 5 000101 s 44 101100 Z 25 011001 W 22 010110 4 56 111000
然后将二进制形式合并成一个串:011101100110000101101100011001010110111000,此时为长度: 6*7=42
根据密文可以知道有一个等号于是删除末尾的两个0,得到二进制串0111011001100001011011000110010101101110,长度40正好是8的倍数
1 2 3 4 5 6 7 01110110+01100001+01101100+01100101+01101110 8位二进制 二进制对应的十进制值 十进制对应ASCII值 01110110 118 v 01100001 97 a 01101100 108 l 01100101 101 e 01101110 110 n
拼接得到解密后的字符串valen
根据站长工具验证,上述结论正确
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 str_dict = {'0' : 'A' , '1' : 'B' , '2' : 'C' , '3' : 'D' , '4' : 'E' , '5' : 'F' , '6' : 'G' , '7' : 'H' , '8' : 'I' , '9' : 'J' , '10' : 'K' , '11' : 'L' , '12' : 'M' , '13' : 'N' , '14' : 'O' , '15' : 'P' , '16' : 'Q' , '17' : 'R' , '18' : 'S' , '19' : 'T' , '20' : 'U' , '21' : 'V' , '22' : 'W' , '23' : 'X' , '24' : 'Y' , '25' : 'Z' , '26' : 'a' , '27' : 'b' , '28' : 'c' , '29' : 'd' , '30' : 'e' , '31' : 'f' , '32' : 'g' , '33' : 'h' , '34' : 'i' , '35' : 'j' , '36' : 'k' , '37' : 'l' , '38' : 'm' , '39' : 'n' , '40' : 'o' , '41' : 'p' , '42' : 'q' , '43' : 'r' , '44' : 's' , '45' : 't' , '46' : 'u' , '47' : 'v' , '48' : 'w' , '49' : 'x' , '50' : 'y' , '51' : 'z' , '52' : '0' , '53' : '1' , '54' : '2' , '55' : '3' , '56' : '4' , '57' : '5' , '58' : '6' , '59' : '7' , '60' : '8' , '61' : '9' , '62' : '+' , '63' : '/' } two='' miwen='dmFsZW4=' print ('密文:' +miwen)if '==' in miwen: miwen=miwen[:-2 ] elif '=' in miwen: miwen=miwen[:-1 ] for char in miwen: for k, v in str_dict.items(): if v == char: mingwen_two = bin (int (k,10 )).replace('0b' , '' ) print (mingwen_two.zfill(6 )) print (k) print (char) two=two+mingwen_two.zfill(6 ) print ('密文的二进制:' +two)print ('密码目前长度:' ,int (len (two)))ten='' yuanwen='' for i in range (int (len (two)/8 )): print (two[8 *i:8 +8 *i]) ten=int (two[8 *i:8 +8 *i], 2 ) print (ten) print (chr (ten)) yuanwen+=chr (ten) print ('明文' +yuanwen)
base64隐写 根据上面的信息可以知道valen对应的base64密文是dmFsZW4=
运行下面的程序
1 2 3 4 5 6 import base64b = '' for i in range (4 ): b = 'dmFsZW4' + chr (52 + i) + '=' print (b) print (base64.b64decode(b))
运行结果
1 2 3 4 dmFsZW4= b'valen' dmFsZW5= b'valen' dmFsZW6= b'valen' dmFsZW7= b'valen'
可以看到多个密文能够对应同一个字符串,这是因为在解密的时候会删除后面几个跟等号数量有关的二进制位,所以会导致不同的密文也能对应同一个明文。
并且删除的二进制位指挥在最后一个字符,并且base最多只有两个等号,所以一共可以有2*2个隐写位可以写,而且并不会影响真实的加密信息。
利用这个想法于是就有了base64隐写
实现过程 读取出一行被加密后二进制信息,目前是base64加密的状态,保存为steg_line
然后将steg_line进行base64解密,然后再去进行加密,得到norm_line,这样是消除伪加密
然后根据steg_line和norm_line进行对比,返回两个字符串的绝对值
然后根据等号的个数pads_num和绝对值diff来对bin_str进行不同的操作
绝对值为0,等号个数为2,此时需要加两个00在bin_str后面
绝对值为0,等号个数为1,此时需要加一个00在bin_str后面
绝对值不为0,需要将绝对值diff转成二进制,同时在前面补0需要补到2*等号个数pads_num的数量上
然后将所有的bin_str进行二进制转成ASCII值得到真的密文
代码实现 base隐写解密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #base64隐写 import base64 def get_base64_diff_value(s1, s2): base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' res = 0 for i in range(len(s2)): if s1[i] != s2[i]: return abs(base64chars.index(s1[i]) - base64chars.index(s2[i])) return res def solve_stego(): with open('1.txt') as f: file_lines = f.readlines() bin_str = '' for line in file_lines: steg_line = line.replace('\n', '') # norm_line = line.replace('\n', '').decode('base64').encode('base64').replace('\n','') norm_line = line.replace('\n', '').encode('utf-8') norm_line = base64.b64decode(norm_line).decode('utf-8') norm_line = base64.b64encode(norm_line.encode('utf-8')).decode('utf-8') norm_line = norm_line.replace('\n', '') diff = get_base64_diff_value(steg_line, norm_line) print(diff) pads_num = steg_line.count('=') if diff: bin_str += bin(diff)[2:].zfill(pads_num * 2) else: bin_str += '0' * pads_num * 2 print(goflag(bin_str)) def goflag(bin_str): res_str = '' for i in range(0, len(bin_str), 8): res_str += chr(int(bin_str[i:i + 8], 2)) return res_str if __name__ == '__main__': solve_stego()
实现过程
加密脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import base64flag = 'flag{valen}' bin_str = '' .join([bin (ord (c)).replace('0b' , '' ).zfill(8 ) for c in flag]) base64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' with open ('0.txt' , 'r' ) as f0, open ('1.txt' , 'w' ) as f1: for line in f0.readlines(): rowstr = base64.b64encode(line.encode('utf-8' )).decode('utf-8' ) equalnum = rowstr.count('=' ) if equalnum and len (bin_str): offset = int ('0b' +bin_str[:equalnum * 2 ], 2 ) char = rowstr[len (rowstr) - equalnum - 1 ] rowstr = rowstr.replace(char, base64chars[base64chars.index(char) + offset]) bin_str = bin_str[equalnum*2 :] f1.write(rowstr + '\n' )

 微信
微信

